↧
Unity初心者がボールごろがしゲームを作る part5


↧
Apache Flink とは
ストリーミング処理に本気で取り組む必要があったので Apache Flink を使ってみました。
Apache Flinkとは?
分散ストリーミング処理エンジンです。
ストリーミングのみならずバッチ処理も行うことができますが、ストリーミングと静的データとを同じインターフェイスで扱うことができます。
- 分散システム
- 協調
- フォルト・トレランス
- データ・ストリーミングにおける分散環境
を提供すると謳っています。
本体はScalaで書かれていますが、java, scala, python* のAPIクライアントが用意されています。
クライアントは一連のオペレーションをデータフローとして記述します。
公式URL: http://flink.apache.org/
2016-03-08 メジャーバージョン(1.0.0) リリース。
2016-05-25 現在, 1.0.3。
Apache Flink のAPI
コアAPIといくつかのオプション的なAPIで構成されています。
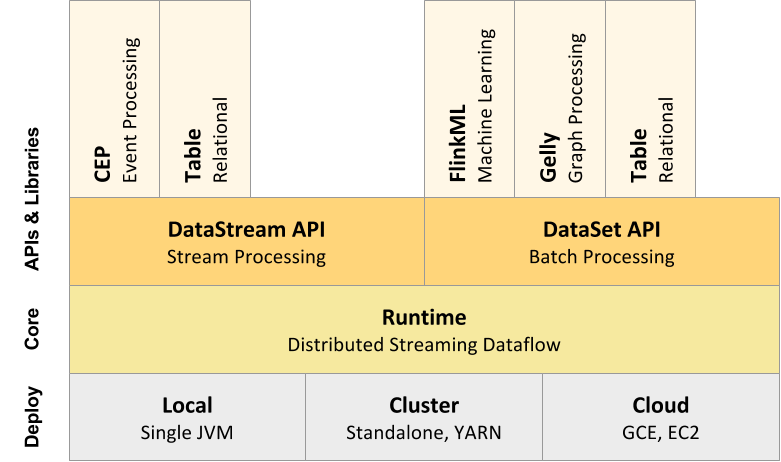
flink api
(https://ci.apache.org/projects/flink/flink-docs-release-1.0/ より)
コアAPI
- DataStream API ・・・ 無限ストリームを扱うAPI。Java, Scala。
- DataSet API ・・・ 静的データを扱うAPI。Java, Scala, Python。
- Table API ・・・ SQLを発行するAPI。Java, Scala。
オプション
- CEP ・・・ 複雑なイベント処理ライブラリ・API
- FlinkML ・・・ 機械学習ライブラリ・API
- Gelly ・・・ グラフ操作ライブラリ・API
構成がApache Sparkと似ています。
Apache Spark vs Flink
非常によく似たコンセプトのApache Spark(のストリーミング)とApache Flinkなので当然違いが気になります。
下記の米Yahooによるベンチマークや
https://yahooeng.tumblr.com/post/135321837876/benchmarking-streaming-computation-engines-at
CapitalOneのエンジニアの方が書かれた下記のスライドをみると違いが良くわかります。
(http://www.slideshare.net/sbaltagi/flink-vs-spark より)
ざっくり違いをまとめるとこんな感じです。
| # | Apache Spark | Apache Flink | 備考 |
|---|---|---|---|
| 処理方式 | micro batch | event driven | micro batchでは厳密なwindow集計が行えないケースがあります。 |
| throughputに対するレイテンシ | 線形増加 | 定数 | 米Yahooのベンチマーク参照 |
| 対応クライアント言語 | scala, java, python, R | scala, java, python | |
| REPL | ◯ | ☓ | |
| Web UI | 処理フローを表現するUIあり | ダッシュボード機能つきUIあり | |
| notebook Web UI | Apache Zeppelin, Jupyter, etc | Apache Zeppelin | ※ FlinkのJupyterから使えるのでは…? |
| YARN cluster | ◯ | ◯ |
この他に、Apache Flinkは
- ユーザ・コードによるOOMが発生しない
- GCを削減する
- 効率的なディスクI/O、ネットワーク転送
- ランタイム・チューニング不要
- 堅牢・安定パフォーマンス
といったアドバンテージがあるそうで、これを見て私は飛びつきましたw
(http://www.slideshare.net/sbaltagi/flink-vs-spark より)
次回、QuickStartに従ってApache Flinkをちょっと触ってみてからクラスタ構築をやってみます。
最終的には、fluentd → kafka → Flink → Apache Zeppelinでストリーミング集計 の流れを構築していきます。
↧
↧
Apache Flinkをインストール
↧
Apache Flink part2 kafkaとfluentdのインストール
Flink2回めはkafkaとfluentdとの連携です。
と言っても、インスコするだけで終わっちゃいました。
なのでFlinkとの連携は次回
↧
Apache Flink + Kafka + Zeppelin 連携でアドホックなストリーミング分析
前回、Apache FlinkとはでFlinkの概要に触れたのですが、今回は実践的にkafkaと連携させ、Apache Zeppelinでアドホックに分析してみます。
Zeppelinを使うのは、単純に、jar作って実行するのが面倒だからです(^_-)-☆
概要

fluentdでデータを収集し、Kafkaにデータを送ります。
Zeppelin上のnotebookからflinkの集計ジョブを実行します。
flinkジョブはKafkaに集約されたストリーミング・データを集計します。
というわけでfluentd, Kafkaをインストールしていきます。
※ この記事ではCentOS 6.7 Finalを使います。またサーバ上ではrootで作業しています。
※ また、jdkはopenJDKの1.8を使用しています。
fluentd, Kafkaインストール
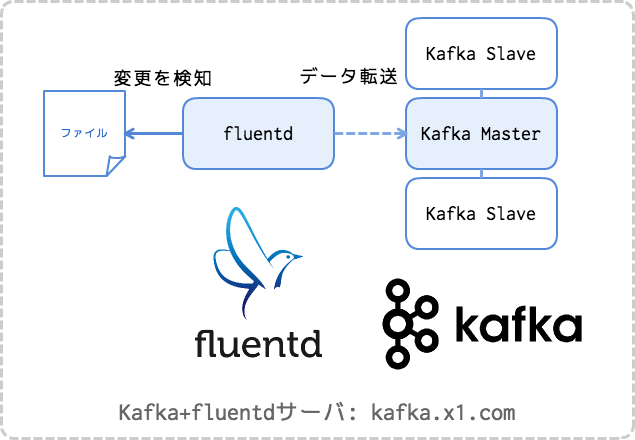
この記事ではfluentdとKafkaを1つのサーバの同居させて使います。
もちろん実際には別のノードにした方が良いケースが多くあるかと思います。
1. fluentd
まずはfluentdからですかね。
fluentdのインストール方法は公式ドキュメントに詳しく書かれています。
ここではRPMを使って td-agent をインストールしていきますが、まずは必須要件から。
ulimitを上げるためlimits.conf を編集します。
vi /etc/security/limits.conf ~ root soft nofile 65536 root hard nofile 65536 * soft nofile 65536 * hard nofile 65536 ~
ntpdがインストールされていない場合はntpdをインストールして起動設定をonにします。
yum -y install ntp
開発ツールをインストールします。
yum groupinstall 'Development tools'
終わったらマシンを再起動します。
あとは次のコマンドを実行するだけです。
curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent2.sh | sh
これでtd-agentがインストールされるので、kafkaプラグインを入れます。
td-agent-gem install fluent-plugin-kafka
2. Apache Kafka
Kafkaのインストールについては詳しい記事がたくさん存在するので、ここでは割愛します。
ここでは下記の記事どおりにkafkaを起動したこととして進めます。
Apache Kafka ―入門からTrifectaを用いた可視化まで―
※ 使用したkafkaのバージョンは kafka_2.11-0.9.0.1 です。
で、このKafkaサーバではzookeeperが2181, kafkaが9092ポートで待ち受けていることとします。
CLIなどを使ってKafka上にトピック stock_index を作っておきます。
KAFKA_HOME=/opt/kafka ZK="localhost:2181" $KAFKA_HOME/bin/kafka-topics.sh --create --topic stock_index --partitions 2 --zookeeper $ZK --replication-factor 1
これでfluentd→kafka連携の準備ができました。
3. fluentdからkafkaへ転送する
ある場所に置いたファイルにデータが追加されたらkafkaに送信するようfluentdの設定ファイルを編集します。
<source> type tail format json path /var/data/index.log pos_file /var/log/td-agent/index.log.pos time_format %Y-%m-%d %H:%M:%S time_key time keep_time_key true tag log.index </source> <match log.**> @type kafka time_format %Y-%m-%d %H:%M:%S time_field time brokers localhost:9092 zookeeper localhost:2181 default_topic stock_index output_data_type json required_acks 1 ack_timeout_ms 1500 </match>
td-agentを再起動します。
/etc/init.d/td-agent start
指定したファイルにデータを書き込むと、kafkaに転送されます。
echo '{"time":"2016-06-20 18:41:05","open":"1.14596","high":"1.14629","low":"1.14589","close":"1.14591","volume":"0","tag":"EURUSD"}' >> /var/data/index.log
これでfluentdとKafkaの準備はおわりです。
※ trifecta(インストールしていたら)や kafka-cli からメッセージ数が増えたことを確認することができます。
Flinkクラスタのインストール
Flinkクラスタの構築も公式ドキュメントの QuickStart に詳しく書いてあります。
この記事では、公式ドキュメントと同じく、masterノード1台とworkerノード2台の合計3台構成でクラスタを構築します。
※ Flinkクラスタの構築は動画でも紹介しています。
Apache Flinkをインストール
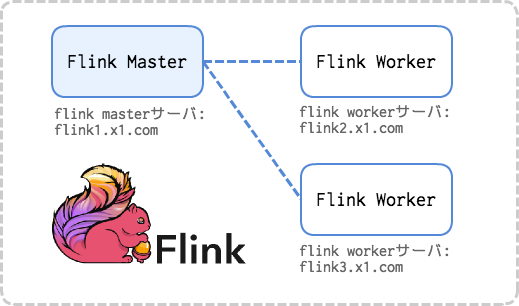
1. JDKのインストール
JDK(>=1.7)をインストールします。
この記事ではopenJDKの1.8を使います。
yum -y install java-1.8.0-openjdk
2. Flinkバイナリの設置
FlinkのダウンロードページからHadoopとscalaのバージョンを選択してバイナリのダウンロード・リンクを取得し、全ノードでダウンロード→展開します。
cd /opt wget http://ftp.jaist.ac.jp/pub/apache/flink/flink-1.0.3/flink-1.0.3-bin-hadoop27-scala_2.11.tgz tar zxvf flink-1.0.3-bin-hadoop27-scala_2.11.tgz ln -nfs /opt/flink-1.0.3-bin-hadoop27-scala_2.11 /opt/flink
/optに解凍し、/opt/flinkというシンボリックリンクを張りました。
3. 設定ファイルの編集
master, workerの全てで conf/flink-conf.yaml の編集を行います。
| jobmanager.rpc.address | masterノードのアドレス(ホスト名でもよい)を指定 |
| taskmanager.heap.mb | workerノードで使用できるメモリ(MB)を指定 |
| taskmanager.numberOfTaskSlots | workerノードで使用できるCPU数を指定 |
| parallelism.default | ジョブの並列数。クラスタ全体で使用可能なCPU数 |
| taskmanager.tmp.dirs | workerノードのテンポラリ・ディレクトリ |
cp -pv /opt/flink/conf/flink-conf.yaml{,.bak}
vi /opt/flink/conf/flink-conf.yaml
~
jobmanager.rpc.port: 6123
jobmanager.heap.mb: 512
taskmanager.heap.mb: 1536
taskmanager.numberOfTaskSlots: 2
taskmanager.memory.preallocate: false
parallelism.default: 6
jobmanager.web.port: 8081
state.backend: jobmanager
taskmanager.tmp.dirs: /tmp
~
master, workerの全てで conf/slaves にworkerのアドレス(ホスト名でもよい)を列挙します。
cp -pv /opt/flink/conf/slaves{,.bak}
vi /opt/flink/conf/slaves
~
flink2.x1.com
flink3.x1.com
~
4. Flinkクラスタの起動
masterノードで起動スクリプトを実行します。
/opt/flink/bin/start-cluster.sh
以上でFlinkクラスタの構築は完了です。
Apache Zeppelinのインストール
最後に、Apache Zeppelinをインストールします。
Zeppelinのインストールは、公式ドキュメントよりもGitHubのREADMEを読んだ方が新しい情報が載っていて良いかと思います。
1. 必須要件のインストール
Zeppelinはフロント部分のビルドにnode.jsを使います。
yum -y install java-1.8.0-openjdk git npm fontconfig-devel
2. ソースコードのビルド
Zeppelinもバイナリはあるのですが、なかなか 0.6にバージョンが上がらないのでソースコードをビルドして使います。
cd /opt git clone https://github.com/apache/zeppelin.git ln -nfs /opt/incubator-zeppelin /opt/zeppelin cd /opt/zeppelin mvn install -Pspark-1.6 -Dspark.version=1.6.1 -Dhadoop.version=2.7.0 -Drat.numUnapprovedLicenses=100 -DskipTests -Ppyspark
Successが表示されたら完了です。
3. Zeppelinの起動
Zeppelinのデーモンを起動します。
cd /opt/zeppelin bin/zeppelin-daemon.sh start
ブラウザからZeppelinにアクセスします。

4. Flink接続設定を行う
Zeppelin のメニューから Interpreter をタップし、 Interpreter の設定ページヘ遷移します。
Flink の設定箇所があるので、
- hostにFlinkマスターのアドレス
- portにFlinkマスターの起動ポート
を設定します。
また、Kafkaと連携するためのjarを Dependencies に入力します。
| artifact | exclude |
| org.apache.flink:flink-connector-kafka-0.9_2.11:1.0.3 | |
| org.apache.flink:flink-streaming-scala_2.11:1.0.3 |
※ コネクタはkafkaのバージョンごとに異なります。このブログではkafka0.9.1+scala2.11を使っているので上記のjarを使いました。

Flinkカテゴリ右上の restart をタップして Interpreter の再起動を行います。
5. notebook からFlink へ接続
Zeppelinのnotebookを新規追加します。
Kafkaの設定をおこない、実行します。

ここまでで接続の確認は終了です。
ZeppelinからFlink を使って集計するサンプルは ZeppelinHub に公開されているので参考になります。
WordCount | ZeppelinHub viewer
次回、Zeppelinからkafkaに蓄積されたストリーミングデータを集計していきたいと思います。
↧
↧
Yogibo ヨギボーで快適ダラダラ開発環境を導入した
Yogiboとはアメリカ発の「快適で動けなくなる」というキャッチコピーのソファー、クッションです。
こういう系のクッションは無印とかも出してますが、でかいのが欲しかったのでYogiboにたどり着きました。
先日インケンの家に導入してすごく快適になったのでご紹介します。
立てかけたり、座ったり、寝転んだりいろんな使い方ができます。
Yogiboのクッションには大きさが3つあり、一番大きいMax、中くらいのMidi、小さいMiniがあります。
Maxは大人がすっぽり入るくらいの大きさです。
最初はMidiでもいいかなと思ったのですが、ショップで座ったら断然Maxが欲しくなりました。

Yogibo Max
身長173cmくらいのインケンでもすっぽり収まります。
背もたれの緑のクッションはYogibo SupportというU時のクッションで、膝に載ってるPC台はTrayboという商品です。


このMax,Support,Trayboをインケンのとバツイチちゃんの2セット導入しました。
バツイチちゃんなんて土日はほぼこの上で生活しているほどです。

Yogiboは色も豊富でこんなにたくさんの色から選べます。

カバーは取り外し可能で洗濯機で洗えます。クッションに張りがなくなってヘタってきたらカバーを洗って乾燥機にかけると張りが復活します。
値段はYogibo Maxが約3万、Yogibo Supportが約1万5千、Trayboが6千円ほどで、2つつづ導入したので全部で10万以上かかりましたが、超快適なぐうたら開発環境ができてとても満足しています。
↧
分散TensorFlowでロジスティック回帰 -Distributed TensorFlow- その1
TensorFlow0.8から並列分散処理がサポートされるようになりました。
大量のデータに対して高コストな計算を行う機械学習でも、たくさんマシンを並べれば数分〜数時間で終わらせることができるのは魅力ですよね。
どうやって分散するのか気になったので、これからやってみます。
最初のパートでロジスティック回帰のアルゴリズムをおさらいし、「分散しないTensorFlow」でロジスティック回帰を実装します。
次のパートで分散TensorFlowでロジスティック回帰による分類を行います。
使うのはTensorFlowお馴染みの、MNISTの数字手書き画像です。
MNIST
ロジスティック回帰とは
ロジスティック回帰モデルは目的変数が1となる確率を予測します。
ロジスティック回帰の活用例
- キャンペーンの反応率
- 土砂災害発生危険基準線の確率
- 医療における症例の発生確率
ロジスティック回帰モデル(多クラス分類)
手書きの数字は0〜9の10個に分類する他クラス分類になるので、シュプリンガーのパターン認識と機械学習を参考に、ロジスティック回帰モデルによる多クラス分類を見ていきます。
多クラスの分布に対しては、事後確率が特徴変換のソフトマックス変換で与えられます。
事後確率
 = y_{k} \big( \phi \big) = \frac{exp(a_{k})}{\sum_{j}exp(a_{j})}")
活性

最尤法を用いてパラメータwを決定する
すべての活性化関数に関するyの微分が必要となります。
")
I は単位行列の要素。
ここから尤度関数を出して式変形すると、多クラス分類問題に対する *交差エントロピー誤差関数* になります。
多クラス交差エントロピー誤差関数
 = - \ln p \big( T \mid w_{1}, ... , w_{K} \big) = - \sum_{n=1}^{N} \sum_{k=1}^{K} t_{nk} \ln y_{nk}")
勾配
ソフトマックス関数の微分に対する結果を使うと・・・
 = \sum_{n=1}^{N} \big( y_{nj} - t{nj} \big)")
これを使っています。

他クラス交差エントロピー誤差関数とソフトマックス活性化関数に対しても、「誤差」")

シングル・ノード版ソースコード
上で得られた式をコードにすると下記のようになります。
TensorFlowは数式とコードの対応が非常にわかりやすいです。
LogisticRegression.py
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
### パラメータの定義
# Parameters
learning_rate = 0.01
training_epochs = 25
batch_size = 100
display_step = 1
### 手書きの数字画像を訓練データに使う
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
x = tf.placeholder(tf.float32, [None, 784], name="x-input") # mnist の画像サイズ 28*28=784
W = tf.Variable(tf.zeros([784, 10]), name="weights")
b = tf.Variable(tf.zeros([10]), name="bias")
### 活性化関数の定義
with tf.name_scope("Wx_b") as scope:
y = tf.nn.softmax(tf.matmul(x, W) + b)
# matmulは行列積を計算する。↑は内積を計算。
y_ = tf.placeholder(tf.float32, [None,10], name="y-input") # 0〜9 10 classes
### 損失関数の定義 交差エントロピー誤差関数のエラーを最小化する
with tf.name_scope("xentropy") as scope:
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
ce_summ = tf.scalar_summary("cross entropy", cross_entropy)
### オプティマイザの定義
with tf.name_scope("train") as scope:
optimizer = tf.train.GradientDescentOptimizer( learning_rate ).minimize( cross_entropy )
init = tf.initialize_all_variables()
### モデルの訓練
# Launch the graph
with tf.Session() as sess:
sess.run( init )
# Training cycle
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int( mnist.train.num_examples / batch_size )
for i in range( total_batch ):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# 訓練フェーズ
_, c = sess.run( [optimizer, cross_entropy], feed_dict={x: batch_xs, y_: batch_ys} )
# 損失の平均
avg_cost += c / total_batch
if (epoch+1) % display_step == 0:
print "Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost)
print "Optimization Finished!"
with tf.name_scope("test") as scope:
correct_prediction = tf.equal( tf.argmax(y, 1), tf.argmax(y_, 1) )
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
accuracy_summary = tf.scalar_summary("accuracy", accuracy)
print "Accuracy:", accuracy.eval({x: mnist.test.images[:3000], y_: mnist.test.labels[:3000]})
# 全ての要約をマージしてそれらを /tmp/mnist_logs に書き出します。
merged = tf.merge_all_summaries()
writer = tf.train.SummaryWriter("/tmp/mnist_logs", sess.graph_def)
Epoch:0025 cost= 26.540901189 Accuracy: 0.896
精度:0.896。結構良いです。
さて、これを分散するように書き換えたいのですが、長くなってきたので次回にします。
余談ですが・・・
TensorFlow0.9から導入されたLinearClassifierを使った、「バイナリ・データのベクトル化→訓練→推定」のチュートリアルが TensorFlow Linear Model Tutorial に掲載されているのでこちらも今度やってみたいです。
↧
分散TensorFlowでロジスティック回帰 -Distributed TensorFlow- その2
分散TensorFlowでロジスティック回帰 -Distributed TensorFlow- その1の続きです。
前回TensorFlowでシングル・ノード版のロジスティック回帰を実装し、MNISTの分類を行いました。
今回はロジスティック回帰を並列実行します。
並列実行環境
並列実行環境として物理マシンを並べても良いのですが、お手軽にDockerコンテナを使います。
CentOS7にDockerを入れ、DockerHubからTensorFlowコンテナイメージを持ってきます。
yum -y install docker # dockerをサービスとして開始 systemctl start docker systemctl enable docker # DockerHubからtensorflowイメージをpull docker pull gcr.io/tensorflow/tensorflow
このイメージはTensorFlowのバージョンが低いので、Dockerfileを作成してTensorFlowをアップグレードします。
vi Dockerfile
~
FROM gcr.io/tensorflow/tensorflow
MAINTAINER x1 <viva008@gmail.com>
EXPOSE 8888 2222
# make directory -> mounted on host
RUN mkdir -p /var/data/shared
# upgrade pip
RUN pip install --upgrade pip
# upgrade tensorflow 0.8 to 0.9
ENV TF_BINARY_URL https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.9.0-cp27-none-linux_x86_64.whl
RUN pip -q uninstall -y tensorflow && \
pip -q install --ignore-installed --upgrade $TF_BINARY_URL
~
コンテナ間でチェック・ポイントを共有するための、共有マウント用ディレクトリ(/var/data/shared)の作成もこのDockerfileで行いました。
docker buildしてイメージの生成を行います。
docker build -t tensorflow:0.9.0 .
TensorFlowの分散処理には下記のロールが必要になります。
- パラメータの計算を並列化するパラメータ・サーバ
- 勾配・損失計算を並列化するワーカー・ホスト
並列化の様子を観察するため、パラメータ・サーバ2台とワーカー・ホスト2台を起動します。
# パラメータ・サーバ1 ps_93 docker run --privileged -td -p 3223:3223 -v /var/data/shared:/var/data/shared --add- host="tensorflow.x1.com:172.xx.xx.xx" --name ps_93 tensorflow:0.9.0 # tensorflow.x1.com はDockerホストのホスト名、172.xx.xx.xxはDockerホストのIPです。 # 各ホストに割り当てるポートを開放しておきます。 # ホストの/var/data/sharedにコンテナの/var/data/sharedをマウントします。 # パラメータ・サーバ2 ps_94 docker run --privileged -td -p 3224:3224 -v /var/data/shared:/var/data/shared --add- host="tensorflow.x1.com:172.xx.xx.xx" --name ps_94 tensorflow:0.9.0 # ワーカー・ホスト1 wk_93 docker run --privileged -td -p 2223:2223 -v /var/data/shared:/var/data/shared --add- host="tensorflow.x1.com:172.xx.xx.xx" --name wk_93 tensorflow:0.9.0 # ワーカー・ホスト3 wk_94 docker run --privileged -td -p 2224:2224 -v /var/data/shared:/var/data/shared --add- host="tensorflow.x1.com:172.xx.xx.xx" --name wk_94 tensorflow:0.9.0
並列実行版ソースコード
公式のDistributed TensorFlow r0.9にはグラフ間レプリケーション・非同期訓練のスケルトンが掲載されているのですが、面倒な勾配の集約をフレームワークに任せたかったのでグラフ間レプリケーション・同期訓練で作成しました。
LogisticRegression.py
#!/usr/bin/env python
#-*- encoding: utf-8 -*-
# vim: tabstop=8 expandtab shiftwidth=4 softtabstop=4
from __future__ import print_function
import tensorflow as tf
import sys
import time
from tensorflow.examples.tutorials.mnist import input_data
# Flags for defining the tf.train.ClusterSpec
tf.app.flags.DEFINE_string("ps_hosts", "",
"Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "",
"Comma-separated list of hostname:port pairs")
# Flags for defining the tf.train.Server
tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
FLAGS = tf.app.flags.FLAGS
# config
batch_size = 100
learning_rate = 0.001
training_epochs = 10
# ホスト間で共有可能なディレクトリを指定します。
board_path = "/var/data/shared/board"
def main(_):
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
worker_num = len(worker_hosts)
# cluster を作成します。
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# ローカル・タスクを実行するサーバを開始します。
server = tf.train.Server(cluster,
job_name=FLAGS.job_name,
task_index=FLAGS.task_index)
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
is_chief = (FLAGS.task_index == 0)
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
# Between-graph replication
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# 更新数のカウンター
global_step = tf.get_variable('global_step', [],
initializer = tf.constant_initializer(0),
trainable = False)
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, shape=[None, 784], name="x-input") # mnist data image of shape 28*28=784
y_ = tf.placeholder(tf.float32, shape=[None, 10], name="y-input") # 0〜9 10 classes
with tf.name_scope("weights"):
W = tf.Variable(tf.zeros([784, 10]))
with tf.name_scope("biases"):
b = tf.Variable(tf.zeros([10]))
with tf.name_scope("softmax"):
y = tf.nn.softmax(tf.matmul(x, W) + b)
with tf.name_scope('cross_entropy'):
#cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), reduction_indices=[1]))
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
# optimizer
with tf.name_scope('train'):
grad_op = tf.train.GradientDescentOptimizer(learning_rate)
# SyncReplicasOptimizerを使うと、同期的に勾配を集約してオプティマイザに渡すことができます。
rep_op = tf.train.SyncReplicasOptimizer(grad_op,
replicas_to_aggregate=worker_num,
replica_id=FLAGS.task_index,
total_num_replicas=worker_num,
use_locking=True)
train_op = rep_op.minimize(cross_entropy, global_step=global_step)
#train_op = grad_op.minimize(cross_entropy, global_step=global_step)
init_token_op = rep_op.get_init_tokens_op()
chief_queue_runner = rep_op.get_chief_queue_runner()
with tf.name_scope('Accuracy'):
# accuracy
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.scalar_summary("cost", cross_entropy)
tf.scalar_summary("accuracy", accuracy)
#saver = tf.train.Saver()
summary_op = tf.merge_all_summaries()
init_op = tf.initialize_all_variables()
print("Variables initialized ...")
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0),
global_step=global_step,
init_op=init_op)
begin_time = time.time()
frequency = 100
with sv.prepare_or_wait_for_session(server.target, config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=True)) as sess:
# is chief
if is_chief:
sv.start_queue_runners(sess, [chief_queue_runner])
sess.run(init_token_op)
writer = tf.train.SummaryWriter(board_path, graph=tf.get_default_graph())
start_time = time.time()
for epoch in range(training_epochs):
batch_count = int(mnist.train.num_examples/batch_size)
count = 0
for i in range(batch_count):
batch_x, batch_y = mnist.train.next_batch(batch_size)
if i % worker_num == FLAGS.task_index:
continue
_, cost, summary, step = sess.run(
[train_op, cross_entropy, summary_op, global_step],
feed_dict={x: batch_x, y_: batch_y})
writer.add_summary(summary, step)
count += 1
if count % frequency == 0 or i+1 == batch_count:
elapsed_time = time.time() - start_time
start_time = time.time()
print("Step: %d," % (step+1),
" Epoch: %2d," % (epoch+1),
" Batch: %3d of %3d," % (i+1, batch_count),
" Cost: %.4f," % cost,
" AvgTime: %3.2fms" % float(elapsed_time*1000/frequency))
count = 0
print("Test-Accuracy: %2.2f" % sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
print("Total Time: %3.2fs" % float(time.time() - begin_time))
print("Final Cost: %.4f" % cost)
#sv.stop()
if is_chief:
sv.request_stop()
else:
sv.stop()
print("done")
if __name__ == "__main__":
tf.app.run()
このソースコードはDISTRIBUTED TENSORFLOW EXAMPLEを大変参考にさせて頂きました。
実行
dockerコンテナに入り上記のLogisticRegression.pyを実行します。
パラメータ・サーバから起動します。
docker exec -it ps_93 /bin/bash root@2acc72e5e58b: python /var/data/shared/LogisticRegression.py --ps_hosts=tensorflow.x1.com:3223,tensorflow.x1.com:3224 --worker_hosts=tensorflow.x1.com:2223,tensorflow.x1.com:2224 --job_name=ps --task_index=0 docker exec -it ps_94 /bin/bash root@08e6eb86c897: python /var/data/shared/LogisticRegression.py --ps_hosts=tensorflow.x1.com:3223,tensorflow.x1.com:3224 --worker_hosts=tensorflow.x1.com:2223,tensorflow.x1.com:2224 --job_name=ps --task_index=1
ワーカー・ホストはマスターノードから起動します。
docker exec -it wk_93 /bin/bash root@a5e04c49edec: python /var/data/shared/LogisticRegression.py --ps_hosts=tensorflow.x1.com:3223,tensorflow.x1.com:3224 --worker_hosts=tensorflow.x1.com:2223,tensorflow.x1.com:2224 --job_name=worker --task_index=0 docker exec -it wk_94 /bin/bash root@bde152d25ffd: python /var/data/shared/LogisticRegression.py --ps_hosts=tensorflow.x1.com:3223,tensorflow.x1.com:3224 --worker_hosts=tensorflow.x1.com:2223,tensorflow.x1.com:2224 --job_name= worker --task_index=1
結果
実行結果です。epoch=10で実行しました。

Test-Accuracy: 0.92 Total Time: 25.24s Final Cost: 47.4627
シングルノード版よりも少し精度が良いという以外な結果に…?
各ノードのtopの様子です。
すべてのCPUが使われているのがわかります。

↧
Tableauタブロー で競馬の格言を検証する part1
タブローで地方競馬のデータから競馬の格言を検証します。
part1は「人気薄の先行馬を買え」
さて、どういった結果になるのでしょうか!?
↧
↧
JVMチューニング: G1GCの使いどころとCMS GCからのマイグレート
Java7 Update4 (java7u4) で正式サポートされたG1GC(ガベージ・ファーストGC)ですが、Java9ではデフォルトGCになることが確定しています。
参考: JEP248
またG1GCは、CMS GCを長期的に置き換えるものとして計画されています。
そこで、どのようなアルゴリズムなのか知っておいたほうが良さそうなので調査しました。
G1GCが向いているケース
G1GCが向いているのは下記の環境です。
- ヒープサイズが大きな環境(6GB以上)
- 一時停止可能時間がシビア(0.5sec未満)
Oracleの 9 ガベージファースト・ガベージ・コレクタによると、CMS GCもしくはParallel GCを使っていて次のいずれかに該当したらG1GCへの切り替えを検討しましょうとのことです。
- Javaヒープの50%超がライブ・データ(≒必要なデータ)で占められている。
- オブジェクトの割当て率または昇格率が大きく変化する。
- ガベージ・コレクションまたは圧縮によるアプリケーションの一時停止の長さが望ましくない(0.5から1秒を超える)。
私はヒープの50%以上がライブ・データで占められており、一時停止可能時間がシビアなアプリケーションをCMS GCで扱っているので、この謳い文句には大変惹かれました。
G1GCの特徴
それでは、G1GCはどのようなアルゴリズムなのでしょうか?
G1GCの特徴は大まかには次の3点になります。
- ヒープを不連続で細かいリージョンという単位で管理する
- 目標停止時間を守って収集を行う
- ガベージ率が高そうなヒープに対して収集・圧縮を集中する
ヒープは均等サイズのリージョン・セットに分割され、若い世代も古い世代もこのリージョンで管理されます。

G1によるヒープの分割 より
G1GCは、ヒープ全体のオブジェクトがライブかどうかを判断する、同時グローバル・マーキング・フェーズを実行し、どのリージョンにガベージ(≒ゴミ)が多いかを認識します。
ガベージでいっぱいとなっている可能性が高いヒープ領域に対して、収集・圧縮を集中するので G1 = ガベージ・ファースト と呼ばれています。
このときG1GCは一時停止予測モデルを使って、指定された一時停止時間目標に基づいて収集するリージョン数を選択します。
この仕組みによりマルチ・プロセッサ環境下での低レイテンシ・高スループットを実現しています。
STW stop-the-world
万能にみえるG1GCにもSTW(stop-the-world)があります。
まず収集の最後に部分的なSTW、コンカレントなクリーンアップ・フェーズがあります。
またCMS GCと同様に、あるリージョンから別リージョンへのオブジェクト・コピー中にアプリケーションが新たなオブジェクトを割り当てた場合、ヒープの枯渇(割当の失敗)が発生します。
これはSTWフル・コレクションを引き起こします。
CMS GCからG1GCへのマイグレート
G1GCの特性が、私の扱っている環境に適していそうだったので、CMS GCからマイグレートしてみることにしました。
マイグレートの際に大変参考にさせて頂いたのがこちらのスライドです。
Garbage First Garbage Collector (G1 GC) – Migration to, Expectations and Advanced Tuning from Monica Beckwith
まずは現状の把握から。
変更前はCMS GCを使っていました。
対象となるアプリケーションは秒間100〜200程度のリクエストを捌いています。
サーバのスペックは
CPU: 8個
メモリ: 26G
メモリ: 26G
です。
javaのバージョンは下記のとおり。
java version "1.8.0_31" Java(TM) SE Runtime Environment (build 1.8.0_31-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.31-b07, mixed mode)
CMS GC時の起動オプション
${JAVA_HOME}/bin/java \
-Xmx13703M \
-Xms13703M \
-Xloggc:gc.log \
-XX:NewRatio=1 \
-XX:SurvivorRatio=2 \
-XX:TargetSurvivorRatio=90 \
-XX:MaxTenuringThreshold=15 \
-XX:+PrintGCDetails \
-XX:+PrintGCDateStamps \
-XX:+UseConcMarkSweepGC \
-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=7900 \
-Dcom.sun.management.jmxremote.authenticate=false \
-Dcom.sun.management.jmxremote.ssl=false \
-Djava.rmi.server.hostname=`hostname -f` \
-classpath ${CLASS_PATH} \
${MAIN_CLASS} \
$@
VisualVMで見たCMS GCのヒープ使用率

細かくマイナーGCを行いつつも、徐々に使用ヒープが増えていき、閾値を超えるとメジャーGCでクリーンアップされている様子がわかります。
マイグレート
上記のスライドp48によると、G1GCはCMS GCよりもCPUを使うとのこと。
停止時間の予測している側面からだけ見てもオーバーヘッドが大きいのは納得。
さて、起動オプションですが、G1GCは目標停止時間を守るアルゴリズムなので、まずは -XX:MaxGCPauseMillis をどのくらいにするかを考えるべきでしょう。
このオプションのデフォルト値は200msです。
これは人間の知覚の限界と言われているので、まあ人間に対してレスポンスを返すようなアプリケーションであれば200msで良い気がしますが。
それからもちろん -XX:+UseConcMarkSweepGC を-XX:+UseG1GC にする必要があります。
その他上記のスライドp52を参照すると、 -XX:SurvivorRatio, -XX:TargetSurvivorRatio, -XX:MaxTenuringThreshold は消してしまえと。
各領域をどのくらいの比率で使うかは G1GC に任せたほうが良いということですね。
あとは マーキング・サイクルを開始するJavaヒープ占有率のしきい値を設定する -XX:InitiatingHeapOccupancyPercent と 適切な世代サイズを出力する -XX:PrintAdaptiveSizePolicyを設定しました。
G1GC時の起動オプション
${JAVA_HOME}/bin/java \
-Xmx13703M \
-Xms13703M \
-Xloggc:/var/log/ultima/gc.log \
-XX:+PrintGCDetails \
-XX:+PrintGCDateStamps \
-XX:+PrintAdaptiveSizePolicy \
-XX:+UseG1GC \
-XX:MaxGCPauseMillis=200 \
-XX:InitiatingHeapOccupancyPercent=50 \
-Dcom.sun.management.jmxremote \
-Dcom.sun.management.jmxremote.port=7900 \
-Dcom.sun.management.jmxremote.authenticate=false \
-Dcom.sun.management.jmxremote.ssl=false \
-Djava.rmi.server.hostname=`hostname -f` \
-classpath ${CLASS_PATH} \
${MAIN_CLASS} \
$@
VisualVMで見たG1GCのヒープ使用率
変更後、VisualVMでヒープ使用率を見てみました。

たまにCPUの使用率がスパイクしますが、おそらくこのタイミングでグローバル・マーキング・フェーズが実行されているのでしょう。
ヒープの使用量は安定しています。
つまり効率的にヒープ領域をライブ・データに割り当てているといって良さそうです。
ただ、別の監視ツールで見るとCPU使用率はやはりCMS GCに比べて増えていました。
まとめ
G1GCよりCMS GCの方が早い、というコメントをたびたびネット上で拝見しますが、環境及びアプリケーション特性によって違う、というのが私の見解です。
※ 事実G1GCの方がCPUを使うのは確かなので、CPUリソースが逼迫していたらG1GCの利用は難しいでしょう。
Oracleが書いている通り、ヒープサイズが大きく目標停止時間がシビアな環境がG1GCに向いているのは間違いないと思います。
GCアルゴリズムも適材・適所ですね。
↧
ジョブ・スケジューラ Rundeck で高機能 cron を実現する
Rundeck
Rundeckとは簡単にいうと高機能なcronです。
cronと言われると、「サーバにログインしてcrontabで編集して…」というのを思い浮かべますが、Rundeckは違います。
Web GUIからスケジューリングします。
実行サーバとRundeckサーバは独立しています。
実行履歴がWeb GUI上から閲覧できます。
Rundeckの機能はまだまだ沢山あるのですが、cronと比較しながらRundeckを紹介していきます。
ジョブをスケジュールする
cron
cronはcrontabコマンドを使い、下記のようなcron書式でジョブの実行スケジュールを記述します。
SHELL=/bin/bash PATH=/sbin:/bin:/usr/sbin:/usr/bin MAILTO=root HOME=/ 10 * * * * /bin/which bash > /dev/null 2>&1 30 0 * * * /bin/echo '00:30' > /dev/null 2>&1
Rundeck
RundeckはWeb GUIもしくはAPIでスケジュールの登録を行います。

cronに似た書式で、秒単位まで指定できます。
(cronは分単位が最小)

書式知らなくても設定できるインターフェイスも用意されています。
コマンドの実行
cron
ローカルでコマンドを実行します。
コマンドもcrontabで書きます。
Rundeck
ローカルで実行するかリモートで実行するか、
コマンドを実行するかスクリプトを実行するか
様々な選択肢があります。
更に、ジョブ同士に依存関係を持たせてワークフローを構築することができます。

当然cronでもsshしてリモート・サーバーでジョブを実行することはできるし、スクリプトを書いてワークフローを構築することもできます。
けれどもRundeckを使えばリモート・サーバもワークフローも可視化され一元管理できます。
Rundeckのワークフロー設定に Strategy(戦略)というのがあるのですが、少しわかりにくいので補足を。。。
A -> B -> C
D -> E -> F
という2つのワークフローがあったときに、
Node-oriented:
node1 node2 A D ↓ ↓ B E ↓ ↓ C F
Step-oriented:
node1 node2
A → B
↓
C E
↓
G ← F
のようになります。
実行履歴の確認
cron
標準出力をファイルにリダイレクトして実行履歴を確認するケースが多いですかね。
デフォルトではmailに通知されます。
/dev/null に標準出力を捨ててしまっているのをよく見かけますが、これだと実行されたかどうかさえ良くわからないですね。
Rundeck

Rundeckでは実行履歴が管理されており、Web GUI上から閲覧できます。
リンクをタップすれば詳細も見れます。
実行結果はどんどん増えていくので、放置するとCPUがリークします。
RDBにインデックス張りましょう。。。
参考: Rundeck との闘争 | 日々是ウケ狙い
スケジュール外実行
cron
スケジュールと関係なく実行したいとき、cronだとcrontab -lでコマンドを表示して、コピペして実行・・・のようなことするのが多いのではないでしょうか。
Rundeck
Rundeckだったら登録済みのジョブはボタンぽちでいつでも実行できます。

タイプミス、コピペミスすることがないですし、cron実行時の書式とターミナルから実行時の書式が違う問題*に出くわすこともありません。
cron書式と実行書式が異なる例)
cron : date +”\%Y\%m\%d
ターミナル: date +”%Y%m%d
※ cronでは%のエスケープが必要なのです。
通知
cron
cronはデフォルトでメール通知がくるようになっています。
スクリプト内でいろいろ書けばその他の通知も可能ですが、仕組みとしてはメール通知以外にありません。
Rundeck
Rundeckはデフォルトでメール通知とWebhook、プラグインでSlack通知などが行なえます。

Slack連携を行うとこんな通知がくるようになります。

High Availability
cron
cronにはHAなどありません。
サーバが死んだらcron設定も飛びます。
Rundeck
RundeckはHA構成を組むことができます。
(クラスタではなくactive-standbyですが)

完全なHA構成の構築方法は後ほど別の記事に書きます。
ワークフローのファイル管理
複数人でワークフローを作成したり閲覧したりする場合にはやはりGitでリポジトリ管理したくなります。
cron
実は設定はファイルで管理できます。
crontab ファイル・パス
でファイルの内容をcronに登録します。
Rundeck
APIでワークフローを登録することができます。
ワークフローの書式はXMLもしくはYamlです。
既存のジョブ設定をダウンロードすることができるので、初回は既存のジョブをダウンロードして改造すると良いかもしれません。

<joblist>
<job>
<description><![CDATA[# Run remote test3
`test.sh`]]></description>
<dispatch>
<excludePrecedence>true</excludePrecedence>
<keepgoing>false</keepgoing>
<rankOrder>ascending</rankOrder>
<threadcount>1</threadcount>
</dispatch>
<executionEnabled>true</executionEnabled>
<id></id>
<loglevel>INFO</loglevel>
<name>test3</name>
<nodefilters>
<filter>exec.docker1.com</filter>
</nodefilters>
<nodesSelectedByDefault>true</nodesSelectedByDefault>
<notification>
<onfailure>
<plugin type='SlackNotification'>
<configuration>
<entry key='webhook_url' value='https://hooks.slack.com/services/.....' />
</configuration>
</plugin>
</onfailure>
</notification>
<schedule>
<dayofmonth />
<month day='*' month='*' />
<time hour='00' minute='00' seconds='*/10' />
<year year='*' />
</schedule>
<scheduleEnabled>true</scheduleEnabled>
<sequence keepgoing='false' strategy='node-first'>
<command>
<description>testsh</description>
<exec>/var/local/test.sh</exec>
</command>
</sequence>
<uuid></uuid>
</job>
</joblist>
これをちょこちょこ変えてcurl経由で実行します。
curl -H 'X-RunDeck-Auth-Token:XXXXX' \
-H "Content-Type: application/xml" \
-d @/path/to/xml
-X POST
http://rundeck:4440/api/17/project/TestProject2/jobs/import?dupeOption=skip&uuidOption=remove
※ 余談ですがyamlではうまくいきませんでした…ダウンロードしたファイル改造しないとダメなのかな。。。
もっと便利にRundeckからGit連携ができるようですね。
rundeckのプロジェクト情報をgitで管理
まとめ
いかがでしょうか。
cronをRundeckに置き換えるだけで幸せになれそうです。
↧
RustのWebフレームワークIronでWebサービスをつくる
この記事では、コンパイルが速い!バイナリ実行!シンタックスがかっこいい!と3拍子揃ったRustでWebサービスを作成します。
HTTPハンドラの部分はIronというフレームワークを使います。
Ironはルーティング等のコア機能といくつかのプラグイン(jsonパーザ等)という素軽い構成のWebフレームワークです。
hyperというもっとプリミティブなフレームワークにビルトインする形で作られています。
- 0. わたしの開発環境
- 1. プロジェクトの作成
- 2. HTTPサービスを実行する
- 3. ルーティングする
- 4. 空のJSONを返す
- 5. 構造体をシリアライズしたJSONを返す
- 6. 1px透過GIFを返す
- 7. ルーティングを別モジュールにする
ソースコードはGitHubで公開しています。
https://github.com/x1-/rust_web_service
0. わたしの開発環境
- OS ・・・ MacOSX 10.10.5
- rust ・・・ 1.14.0
- ビルドシステム ・・・ Cargo
- IDE ・・・ emacs + racer + company
rustのインストールは公式サイトに書いてある通りにするのが一番良さそうです。
rustupがcargoのセットアップからrustcのインストールまで行ってくれます。
※2017.01.05 追記) Rust Version Manager, rsvmの導入を検討しても良いかもしれません。
1. プロジェクトの作成
Cargoを使ってWebサービス用のプロジェクト rust_web_service を作成します。
$ cargo new rust_web_service --bin
$ cd rust_web_service
$ tree -a
.
├── .git
│ ├── HEAD
│ :
├── .gitignore
├── Cargo.toml
└── src
└── main.rs
cargo new は git init も同時に行ってくれます。
Cargo.toml , main.rs にはそれぞれ次のように初期コードが出力されます。
わかりやすいですね。
Cargo.toml
[package] name = "rust_web_service" version = "0.1.0" authors = ["x1- <viva008@gmail.com>"] [dependencies]
main.rs
fn main() {
println!("Hello, world!");
}
main()関数はバイナリのランタイムに実行される関数です。
このまま特に編集しないで実行できます。
$ cargo run
Compiling rust_web_service v0.1.0 (file:///Users/xxxx/repos/rust_web_service)
Finished debug [unoptimized + debuginfo] target(s) in 0.43 secs
Running `target/debug/rust_web_service`
Hello, world!
cargoによりコンパイル&実行されてコンソールに Hello World! が表示されます。
2. HTTPサービスを実行する
Ironフレームワークを使ってHTTPサービスを実行します。
Cargo.toml にIronへの依存を追加します。
[package] name = "rust_web_service" version = "0.1.0" authors = ["x1- <viva008@gmail.com>"] [dependencies] [dependencies.iron] version = "*"
Iron に用意されている examples/hello.rs を参考に main.rs を変更します。
main.rs
extern crate iron;
use iron::prelude::*;
use iron::status;
fn main() {
Iron::new(|_: &mut Request| {
Ok(Response::with((status::Ok, "Hello world!")))
}).http("localhost:3000").unwrap();
}
これを実行するとポート3000番にバインドしてHTTPサーバが起動します。
ブラウザから http://localhost:3000 にアクセスすると、 Hello world! が表示されます。

Iron::new() の中の |_: &mut Request| {..} はクロージャです。
Rustのクロージャはパイプ(|)の間に書きます。
see: クロージャ|プログラミング言語Rust
3. ルーティングする
エンドポイントを増やせるようにルーティングします。
ルーティングも examples/simple_routing.rs を参考に、 main.rs に書いていきます。
extern crate iron;
use std::collections::HashMap;
use iron::prelude::*;
use iron::{Handler};
use iron::status;
struct Router {
// キーにパス、値にハンドラを取るHashMap。
routes: HashMap<String, Box<Handler>>
}
impl Router {
fn new() -> Self {
Router { routes: HashMap::new() }
}
fn add_route<H>(&mut self, path: String, handler: H) where H: Handler {
self.routes.insert(path, Box::new(handler));
}
}
impl Handler for Router {
fn handle(&self, req: &mut Request) -> IronResult<Response> {
match self.routes.get(&req.url.path().join("/")) {
Some(handler) => handler.handle(req),
None => Ok(Response::with(status::NotFound))
}
}
}
fn main() {
let mut router = Router::new();
router.add_route("hello".to_string(), |_: &mut Request| {
Ok(Response::with((status::Ok, "Hello world !")))
});
router.add_route("error".to_string(), |_: &mut Request| {
Ok(Response::with(status::BadRequest))
});
let host = "localhost:3000";
println!("binding on {}", host);
Iron::new(router).http(host).unwrap();
}
また cargo run を実行します。
今度はブラウザから http://localhost:3000/error にアクセスすると 400 Bad Request が返るようになります。

4. 空のJSONを返す
次は空のJSONを返すエンドポイントを作成します。
/json にアクセスすると空のjsonが返るようにします。
use iron::headers::ContentType;
を追加して、
router.add_route(“hello”.to_string()… の部分を変更します。
main.rs
extern crate iron;
use std::collections::HashMap;
use iron::prelude::*;
use iron::{Handler};
use iron::status;
// ↓ ここを追加
use iron::headers::ContentType;
~省略~
// hello から json に変更
router.add_route("json".to_string(), |_: &mut Request| {
Ok(Response::with((ContentType::json().0, status::Ok, "{}")))
});
cargo run を実行します。
ブラウザから http://localhost:3000/json にアクセスすると空のjsonが返ります。

examples/content_type.rs にあるように、 Content-Type はいろいろな方法で指定できるようです。
json を出力するなら ContentType::json().0 を使うのが一番スマートに思いますが、 image/gif のように予めメソッドが用意されていない Content-Type を使いたいときは mime!(Image/gif); を使うのが直感的に感じました。
5. 構造体をシリアライズしたJSONを返す
空のJSONを返しても意味が無いので(笑)、構造体をシリアライズしたJSONを返すように修正します。
構造体のシリアライズにはrustc_serialize を使うので、まずは Cargo.toml を変更します。
Cargo.toml
[package] ~省略~ [dependencies] rustc-serialize = "*" [dependencies.iron] version = "*"
main.rs に Letter という構造体を作成します。
main.rs
extern crate iron;
extern crate rustc_serialize;
use iron::status;
use iron::headers::ContentType;
use iron::prelude::*;
use rustc_serialize::json;
// 構造体
// #[derive(RustcEncodable)] ≒ シリアライズ可能属性(rustc_serializeのattribute)
#[derive(RustcEncodable)]
pub struct Letter {
title: String,
message: String
}
~省略~
ついでに、 fn main() 内で add_route していたクロージャも 名前付き関数に切り出します。
main.rs
extern crate iron;
extern crate rustc_serialize;
use iron::status;
use iron::headers::ContentType;
use iron::prelude::*;
use rustc_serialize::json;
#[derive(RustcEncodable)]
pub struct Letter {
title: String,
message: String
}
struct Router {
~省略~
}
fn json(_: &mut Request) -> IronResult<Response> {
let letter = Letter {
title: "PPAP!".to_string(),
message: "I have a pen. I have an apple.".to_string()
};
let payload = json::encode(&letter).unwrap();
Ok(Response::with((ContentType::json().0, status::Ok, payload)))
}
fn bad(_: &mut Request) -> IronResult<Response> {
Ok(Response::with(status::BadRequest))
}
fn main() {
let mut router = Router::new();
router.add_route("json".to_string(), json);
router.add_route("error".to_string(), bad);
let host = "localhost:3000";
println!("binding on {}", host);
Iron::new(router).http(host).unwrap();
}
rustc_serialize::json の encode メソッドに構造体を渡すだけでシリアライズできます。
cargo run を実行してブラウザから http://localhost:3000/json にアクセスすると今度はシリアライズされたJSONが返ります。

ところで、 _: &mut Request の _ ですが、これは名前無し引数を表します。
インターフェイスとして Request を引数にとりますが、関数内では使用していないのでこんなことをしています。
&mut はミュータブル参照です。
ミュータブル参照に束縛された変数は変化しうります。
ミュータブル参照とは何ぞや、とかRustの超重要概念である参照・借用 については プログラミング言語Rust をご一読頂くのが良いかと思います。
6. 1px透過GIFを返す
Webサービスあるあるで、1px透過GIFを返すエンドポイントも作成します。
今度は mime クレイトを使うので、また Cargo.toml を変更します。
Cargo.toml
[package] ~省略~ [dependencies] mime = "*" rustc-serialize = "*" [dependencies.iron] version = "*"
main.rs に mime クレイトと rustc_serialize::base64 を追加します。
mime は Gifの Content-Type を指定するために使います。
rustc_serialize::base64 は 1px透過GIFのBase64文字列をデコードするために使います。
main.rs
#[macro_use] extern crate mime; extern crate iron; extern crate rustc_serialize; use iron::status; use iron::headers::ContentType; use iron::prelude::*; use rustc_serialize::base64::FromBase64; use rustc_serialize::json;
/gif エンドポイントを追加します。
main.rs
~省略~
fn bad(_: &mut Request) -> IronResult<Response> {
Ok(Response::with(status::BadRequest))
}
fn gif(_: &mut Request) -> IronResult<Response> {
// 1px透過GIF文字列
let px1 = "R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==";
Ok(Response::with((mime!(Image/Gif), status::Ok, px1.from_base64().unwrap())))
}
fn main() {
let mut router = routing::Router::new();
router.add_route("json".to_string(), json);
// /gifを追加
router.add_route("gif".to_string(), gif);
router.add_route("error".to_string(), bad);
let host = "localhost:3000";
println!("binding on {}", host);
Iron::new(router).http(host).unwrap();
}
cargo run を実行してブラウザから http://localhost:3000/gif にアクセスするとgifが返ります。

rustc_serialize::base64::FromBase64 トレイトの from_base64() メソッドは、 str と u8に対して実装されています。( str と u8 で使えると思って頂ければと)
で、 Result
↑の例では px1.from_base64().unwrap() と、特に注意を払わず Vec
※ この例では px1 が デコードできることは変化しないので、 unwrap() で十分ですが。
7. ルーティングを別モジュールにする
最後に、ルーティングの部分を別モジュールに切り出します。
routing.rs を作成します。
routing.rs
extern crate iron;
use std::collections::HashMap;
use iron::{Handler};
use iron::status;
use iron::prelude::*;
pub struct Router {
// Routes here are simply matched with the url path.
routes: HashMap<String, Box<Handler>>
}
impl Router {
pub fn new() -> Self {
Router { routes: HashMap::new() }
}
pub fn add_route<H>(&mut self, path: String, handler: H) where H: Handler {
self.routes.insert(path, Box::new(handler));
}
}
impl Handler for Router {
fn handle(&self, req: &mut Request) -> IronResult<Response> {
match self.routes.get(&req.url.path().join("/")) {
Some(handler) => handler.handle(req),
None => Ok(Response::with(status::NotFound))
}
}
}
main.rs で routing モジュールを使うように変更します。
main.rs
~省略~
use rustc_serialize::json;
// ↓この行を追加
mod routing;
#[derive(RustcEncodable)]
pub struct Letter {
~省略~
fn main() {
// router = Router::new() から router = routing::Router::new() に変更
let mut router = routing::Router::new();
router.add_route("json".to_string(), json);
~省略~
}
今回は以上になります。
rust によるWebサービスはもっと深掘りしてみたいと思います。
↧
Real-Time Google Finance API を使って株価を取得する
日本ではフリーでオンラインの株価取得APIが全然ありません。
オンラインで株価を取得しようとすると下記のような状況です。
- Yahooファイナンスをスクレイピング -> Yahooファイナンスに禁止されている
- Google Finance API -> 公式ページに「今はもう使えないよ」
- kabu.com API -> 法人向け。個人には未提供
- 楽天証券RSS, 岡三RSS -> アカウントとExcelが必要
- k-db.com -> CSV。リアルタイム性はなし
しかしGoogle Financeのドキュメントなし非公式APIが存在しており、こちらを使ってリアルタイムに株価を取得することができそうです。
Google Finance
このAPI、実はGoogle Financeで使われています。

ということは、恐らくGoogle Financeで利用しているデータと同じものが得られるはず。
上記のURLをブラウザで開くと、ヘッダー部分とCSV部分で構成されているようなテキストが返ってきます。
APIの使い方
パラメータ
| パラメータ | 意味 | 備考 |
|---|---|---|
| q | 銘柄コード | インデックス系は特殊なのでGoogle Financeで要確認。 |
| x | 市場 | 日本の株式はほぼTYO。 マザーズも大証もTYO。 日経225インデックスはNDEXNIKKEI |
| i | ティックの長さ(秒) | ローソクの期間。日足だったら86400、5分足なら300。 |
| p | 期間 | データ取得期間。1年=1Y、2ヶ月=2M、3日=3d、40分=40m |
| f | 取得する値 | d=日時,c=終値,o=始値,h=高値,l=安値,v=出来高 |
| df | わかりません | |
| auto | わかりません | |
| ts | 開始日時? | |
| ei | セッションキー? |
このAPI、実際に使ってみると結構クセがあることがわかります。
まず◯日〜◯日まで取得、みたいな期間開始指定での値取得ができません。
常にリアルタイムな日時からの指定期間分を返します(要はrealtime apiなんですね)。
また分足で10年、みたいな大量データが返って来そうなパラメータを指定すると、途中でデータが切れます。
ページング機能もありません。
過去データの取得は別のものを使った方が良さそうです。
レスポンスの見方
APIを叩くと下記のようなレスポンスが返ってきます。

データの意味は図に記した通りなのですが、時刻部分だけ少し変わっています。
時刻のデータは a で始まるタイプと数字のみのものがあります。
どのように見るかといいますと、
a で始まる時刻の先頭 a を取るとUNIX時刻になるのでこちらを基準にします。
a で始まらない時刻は 時刻列の数値に INTERVAL を掛けたものを a で始まる時刻
に足した値が当該時刻となります。
つまり・・・
- a で始まる時刻: aを取った文字列がUNIX時刻
- a で始まらない時刻:
a で始まる時刻 + INTERVAL × この列の数値
です。
1つのデータ内に複数の a 始まりの時刻が出現するケースもあるので、a 始まりの時刻が出現する毎に基準となる時刻を変更する必要があります。

まとめ
少々クセはあるものの、リアルタイムで株価を取得できる貴重なAPIです。
ティック(ローソク)の種類が多いのも良いです。
次回、これを使ってslack-botを作ってみたいと思います。
↧
↧
Tableauタブロー で競馬の格言を検証する part2
久々にyoutube投稿しました
part2は夏は牝馬が強いの巻
↧
Tableauタブロー で競馬の格言を検証する part3
part3は短距離戦では大型馬を狙えの巻
↧
運動嫌いのエンジニアが暗闇トランポリンに行ってみた
運動嫌いのエンジニアこと、バツイチです。
最近ちまたで暗闇フィットネスが流行っていますよね。
私もこのたび意を決して暗闇トランポリンの体験レッスンに行ってきましたので、記事を書きました。
「暗闇トランポリン」とは?

ABOUT | JUMP ONE
暗闇の中で、クラブのような音楽と照明とともにテンション高くトランポリンを飛ぶ新感覚フィットネスです。
チェコが発祥で、ヨーロッパ、アメリカ、香港と世界中でブームになっているようです。
日本には2016年3月初上陸しました。
私が体験レッスンに行ってきたのは銀座にスタジオのある JUMP ONEというところです。恐らく暗闇トランポリンの最大手です。
こちら、 ホット・ヨガのLAVA のグループ企業が運営しています。
see: https://www.venturebank.co.jp
ちなみに暗闇サイクリングの FeelCycle もこちらのグループ企業が運営しているようですね。
がんばって行ったわけ
運動嫌いの私はふだん全く運動をしません。
しかしどんどんぶよぶよになっていくボディは気になるわけです(いわゆる締りのない身体)。
ぶよぶよだけでなく、職業病である肩こり・腰痛にも運動した方がよいはず…!
わかってはいるものの、そもそも疲れることや息が上がることが大っ嫌いなので、大抵の運動が3日坊主になってします。
自分でもそれを重々承知しており「どうせ何かはじめても続かないだろう」と何にも手を出さずにここまできたわけです。
だがしかし・・・!
ここで習慣を断ち切らないといつまでも変われません。
そこで下記の条件が揃っている暗闇トランポリンならば続けられそうだったので体験してみることにしました。
- 楽しそう(第一条件)
- 周りについて行けなくても恥ずかしくない(暗闇だから見られないはず…)
- 会社帰りに行ける(最終21時からのレッスンがある)
- 持ち物が少ない(フェイスタオル、バスタオル無料貸し出し)
- 体幹が鍛えられる
※ ダイエットの知識だけはある私は、以前からトランポリンがカロリー消費効率の良いこと、体幹に効くこと、は存じておりました。
予約を取る
やる気を失わないうちに体験レッスンを予約しようとJUMP ONEのサイトを開きます。
どうやらWeb予約できるようで一安心です。
電話のみの予約受け付けだったら確実にここで断念していました。
PRICEページを開いて料金を確認します。
● トライアルチケット【Webクレジットカード決済】 ¥3,000(税抜) ● トライアルチケット【店舗現金決済】 ¥3,500(税抜) ※ミネラルウォーター・フェイスタオル・バスタオル付き(各1セット)
クレカで即決済すると¥3,000、店舗支払いだと¥3,500です。
良く出来てるなーと思いました。
店舗支払いだったら、だんだん面倒になって行かなくなってしまうかもしれません。
そこをクレカで事前に支払わせることで「お金を払ったのだから行かなくては」という気持ちにさせ、予約キャンセルを未然に防ぐとともに取り逃しを防いでいます。
このビジネスモデルを考えた方も、実は運動が嫌いな面倒くさがりなのではないかと親近感が湧いてしまいました。
自分を追い込むためにもWeb決済でトライアルチケットを購入。
とりあえず一仕事終わった気持ちです。
余談ですが、平日夜や休日などはとても人気で予約を取るのが大変でした。。。
初上陸から1年たった今でも人気なのですね。
いざスタジオへ
さて、いざスタジオに入ると、明るいスタッフさんたちが「こんにちは!JUMP ONEへようこそ!」と元気よく挨拶してくださいます。
普通に考えたら明るい感じの良い接客なのでしょうが、普段どっぷりエンジニアの世界にいる私は眩しすぎて若干引き気味です。
すでに気持ちの面で負けています。
体験レッスン前に
何はともあれ逃げ出すわけにもゆかず靴をぬいでスタッフさんに言われるがままカウンターに向かいました。
ここで名前を告げると「○時からのバツイチさまですね」と予約確認が行われ、タオル、ミネラルウォーター、体験の説明書き、利用者用のおしゃれブレスバンドを渡されます。
これを持ってロッカーへ行き、着替えてまた戻ってきます。
ロッカーは鍵式のものではなく暗証番号を自分で決めてロックするタイプのものでした。
たしかに、鍵式ロッカーだとフィットネス中に鍵が邪魔になってしまうのでよく考えられているなーと感心した次第です。

さて着替えて戻ると、椅子に座ってお待ち下さいね〜と声を掛けられます。
言われたとおり座って、何となくまわりを見ると、体験者1名にスタッフ1人がついてロックオンされてる・・・!
と思っていたら私のところにも早速スタッフさんが。
「JUMP ONEのことはどこで知ったんですか〜?」などの当たり障りのないことを聞かれただけなのですが、ここでもテンションについていけず引きつり気味に。
帰りたい私とがんばる私で葛藤していたらスタッフさんがそっと席を外してくれました。
あー良かった。
1人になってぼんやり周りをみると、どうやら体験者は全員女性のようです。
更によく見ると割りとみなさん細身です。
どうも私のように「運動嫌いだけどなんとかできそうなやつを探してきた」という不純な動機ではなく「運動が好きで楽しそうだからきた」という純粋な気持ちで来ているように見えます。
まずい…!私だけついていけなくなったらどうしよう…!
不安マックスです。
レッスン開始
レッスン開始10分前になると、体験レッスンの方はスタジオにお入りくださいと指示されます。
この10分間でインストラクターさんがトランポリンの使い方や基本の動きを教えてくれるわけです。
基本の動きというのは、腹筋の力で足を引き上げるジャンプや、お腹をひねりながらのジャンプ、トランポリン上でのボックス・ステップなどです。
この基本の動き練習だけで息が上がり帰りたくなりました。
私1人ぜーぜー言いながらタオルで汗を拭いている中、まわりは割りと涼しい顔です(このとき汗を拭いていたのは私だけでした)。
なんなら休憩中にまで飛んでいる方もいらっしゃいました。
5分で息が上がる・・・トランポリンの疲れ方すごい
休憩も束の間、アップテンポな音楽とともにレッスンが開始します。
「5分で疲れたのに、45分間も耐えられるんだろうか・・・?」という思いが私の中でぐるぐるします。
そんな私の気持ちはよそに、インストラクターさんは音楽に合わせたメロディアスな口調で「まずは基本のジャンプ〜。お腹に〜足を〜引き上げて〜ワン〜」とプログラムを進行させていきます。
基本の動作練習の比じゃないくらい疲れます。
非常に汗をかくので腕時計をしている人はほとんどいなかったのですが、私は後何分で終わるか確認したいために防水の腕時計をして望みました。
で、ちょいちょい時間を確認していたわけですが、だいたい10分で足が上がらなくなりジャンプが辛くなってきます。
そしておよそ15分ごとに給水と汗拭き休憩がありました。
この小休憩を区切りとして、曲が変わったり、ダンベルを使って違う動作を行ったりします。
「ツライ、もう無理」なタイミングで給水できるので、なんとかもうひと頑張りできる感じでした。
※ 私は水の配分を考えずに最初に飲みすぎてしまったので、後半お水が足りなくなってしまいました(´;ω;`)
しかし・・・運動嫌いな私なのですが、はじめてから30分くらいしてから何となく楽しくなってきたのです。
これがランナーズハイってやつなのかもしれません。
そしてプログラムも30分を過ぎた頃から、「ジャンプしながらYeah!」みたいな、ノリノリモードになってくるのですが、
私も一緒になって「Yeah!Hoo!」と言いながらジャンプしていました。
こういうのが暗闇の良いところですね。
シャイな日本人でもちょっとハードル超えられます。
結局逃げ出すタイミングを失い、最後までプログラムをやりきりました。
決してあっという間とはいえない45分間でしたが、最後には爽快感が残っていました。
レッスン後
レッスンが終了したら、バスタオルを持って更衣室に向かいます。
このときにアンケートをご記入くださいと、用紙を渡されました。
更衣室にはシャワー室が10個くらいあります。
1レッスン20数名だし、続けて次のレッスンを受けられる方もいるので、割りと並んだりせずにシャワーを使うことができます。
スタジオ自体ができて1年くらいなのでシャワー室もきれいで清潔でした。
もちろん、シャンプー、ボディソープ、クレンジング、ドライヤー完備です。
シャワーを浴びて着替え、アンケートに記入して受付に行くとまたスタッフさんに捕まります(笑
「今日ご入会頂くと入会金+登録料、合わせて9,000円お得」とのこと。
押しに弱い私は結局入会してしまうのですが、この辺の料金システムもうまいなーと。
後日入会したくなっても、今日でなければ9,000円余分にかかるので必然的に即断を迫られていることになるわけです。
このフレームワークに則れば、どのスタッフさんがご案内しても、特にテクニック入らずで「考える余地を与えないで即断を迫る」ことができる。
さすがLAVA系列です。
しかしトランポリン自体は爽快だし、少しがんばってみようかな。
まずは習慣を変えなくては。
JUMP ONEのビジネスに思いを馳せてみる
さいごにJUMP ONEの料金等から売上高、営業利益等を想像してみたいと思います。
JUMP ONEの料金体系は下記のとおりです。
-
通常メンバープラン
- マンスリーメンバー ¥14,800・・・月30回通える
- マンスリー4メンバー ¥12,800・・・月4回通える
-
チケットメンバープラン
1回券 クレカ決済:¥4,000、現金決済:¥4,500
通常メンバープランで、月の利用可能枠以上にレッスンを受けたいときには「プラスワンチケット」があります。
プラスワンチケット クレカ決済:¥2,000、現金決済:¥2,500
マンスリー4メンバーとマンスリーメンバーは ¥2,000 しか変わらないので月に6回以上レッスンを受ける場合はお得です。
更にウェブページにも書いてありますが、初回は入会金¥5,000、登録料¥4,000、会員カード発行料¥1,000がかかると書いてあります。
体験レッスンの当日に入会すると会員カード発行料¥1,000以外は無料になるので、多くの人は入会金、登録料は支払っていないでしょう。
上にも書きましたがこれは所謂見せ玉ですね。
料金体系はざっくりこんな感じです(※詳細は公式ページをごらんください)。
次に1つのスタジオで行われているプログラムですが、45分のレッスンが平日は7:00から21:45まで、休日は10:00から18:15くらいまであります。(休日は少し変則的で、土日祝日で若干異なるので18:15くらい、と書かせて頂きました。)
数えてみると
平日13コマ、土曜・祝日7コマ、日曜8コマです。
※水曜日は休みです。
2017年3月を例に1ヶ月のレッスン数をカウントしてみると、
(平日 × 22) + (土曜・祝日 × 5) + (日曜 × 4) = 353 レッスン
実に350強ものレッスンが行われているのが分かります。
ちなみに1レッスンのトランポリンの数は27個なので、最大27人まで受講できます、
ここから月会費を払っている会員がどのくらいいるのか推測してみます。
トランポリンがフルに埋まったとすれば、
9,531 = 353 × 27
最大9,531名が受講できます。
実際の予約状況を見ると平均80%くらいは埋まっているので
7,624.8 = 9,531 * 0.8
1名のメンバーがひと月に来店する平均回数を5回とすると
1,524.96 = 7,624.8 / 5
1,525名程度の会員がいるのではないかと推測できます。
¥22,570,000 = 1,525 * ¥14,800
月の売上高は2千万くらいでしょうかね。
銀座店ではインストラクターさんが23名ほど在籍しているようです。
会員の入会受付などの事務作業もすべてインストラクターさんがされているとのことなので、実質的に23名で2千万を売り上げていると考えてよさそうです。
彼らの給与はいくらになるのでしょう?
エン・ジャパン掲載のJUMP ONE求人情報によると正社員で月給23万円以上+各種手当+決算賞与とのことです。
保険等を加味すると給料の倍額の費用がかかると考えて
¥10,580,000 = ¥230,000 * 2 * 23名
売上の半分は人件費にかかる計算になります。
その他毎月の固定費としてはスタジオの賃貸料、タオルのクリーニング費用等でしょうか。
それでも1,000万程度の営業利益が上がっていることが考えられます。
更に売上を増やそうと思ったら、スタジオをスケールして会員数を増やすことになるのでしょうね。
(人気枠は予約が大変な状況)
だから新規店舗が続々オープンしているのかな。
↧
imply を使ってリアルタイム集計
以前Druidとpivotを使って、twitterデータを可視化というのをやりましたが、Druidやpivotが一緒にパッケージ化されインストールしやすくなったimplyを使って、もっと簡単にリアルタイム集計をしてみたいと思います。
implyは以下のツールがセットになったイベント集計プラットフォームです。
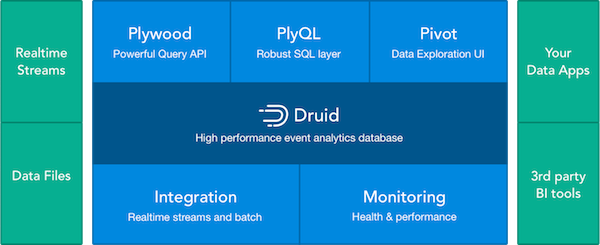
DruidをベースにBIツールのPivotや、DruidのdatasourceをSQLライクに記述できるPlyQL、ラージデータセットを扱う時に便利なJavaScript libraryのPlywoodが含まれています。
implyにはQuickstart用の設定が入ってるので、簡単に試すことができます。
今回はimplyを入れたサーバーとは別のkafkaからデータを取ってきて、pivotで表示するところをこちらのチュートリアルをベースにやっていきたいと思います。
kafkaの準備
まずは、外部のkafkaサーバーを用意し、そこにFluentdとかでJSONで以下のようなデータを入れます。
cd /opt/kafka_2.11/
./bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic sample --from-beginning
{"date":"2017-04-05 06:23:41","ua_name":"Chrome","ua_category":"smartphone","os":"Android","os_version":"5.0","browser_type":"browser","browser_version":"57.0.2987.110"}
{"date":"2017-04-05 06:31:48","ua_name":"Chrome","ua_category":"smartphone","os":"Android","os_version":"5.0","browser_type":"browser","browser_version":"57.0.2987.110"}
{"date":"2017-04-05 07:42:18","ua_name":"Safari","ua_category":"smartphone","os":"iPhone","os_version":"9.1","browser_type":"browser","browser_version":"9.0"}
日時はUTCで入れます。ローカルタイムで入れるとdruidから弾かれます。
implyの設定
kafkaが用意できたらimplyの設定をしていきます。
まずはダウンロードしてきて解凍
tar -xzf imply-2.0.0.tar.gz cd imply-2.0.0
次にdruidのquickstartのkafka設定ファイルを修正します。
vi imply-2.0.0/conf-quickstart/tranquility/kafka.json 一番下にある以下の行をコメントを外します !p95 tranquility-kafka bin/tranquility kafka -configFile conf-quickstart/tranquility/kafka.json
上のコメント外したファイルにdatasourceの設定をします。
中味はこんな感じにしました。
vi conf-quickstart/tranquility/kafka.json
{
"dataSources" : [
{
"spec" : {
"dataSchema" : {
"dataSource" : "sample",
"parser" : {
"type" : "string",
"parseSpec" : {
"timestampSpec" : {
"column" : "date",
"format" : "yyyy-MM-dd HH:mm:ss"
},
"dimensionsSpec" : {
"dimensions" : [
"date",
"ua_name",
"ua_category" ,
"os",
"os_version",
"browser_type",
"browser_version"
]
},
"format" : "json"
}
},
"granularitySpec" : {
"type" : "uniform",
"segmentGranularity" : "hour",
"queryGranularity" : "none"
},
"metricsSpec" : [
{
"type" : "count",
"name" : "count"
}
]
},
"ioConfig" : {
"type" : "realtime"
},
"tuningConfig" : {
"type" : "realtime",
"maxRowsInMemory" : "100000",
"intermediatePersistPeriod" : "PT10M",
"windowPeriod" : "PT10M"
}
},
"properties" : {
"task.partitions" : "1",
"task.replicants" : "1",
"topicPattern" : "sample"
}
}
],
"properties" : {
"zookeeper.connect" : "localhost:2181",
"druid.discovery.curator.path" : "/druid/discovery",
"druid.selectors.indexing.serviceName" : "druid/overlord",
"commit.periodMillis" : "15000",
"consumer.numThreads" : "2",
"kafka.zookeeper.connect" : "kafka-server:2181",
"kafka.group.id" : "kafka",
"serialization.format" : "smile",
"druidBeam.taskLocator": "overlord"
}
}
timestampSpecにjsonのdateの形式を入れて、dimensionsにkafkaに入れたjsonの項目名を入れてます。
topicPatternにはkafkaのtopic名、kafka.zookeeper.connectに上で設定したkafkaサーバーのアドレスを入れます。
とりあえずcountだけ計測するようにmetricsSpecを設定します。
implyの起動
以下のコマンドでdruidやpivotなどが一括で起動します。
bin/supervise -c conf/supervise/quickstart.conf
起動したらkafkaにデータを流してみましょう。
tail -f var/sv/tranquility-kafka.log
こんな感じのログが出ると思います。
2017-04-05 08:38:40,721 [KafkaConsumer-CommitThread] INFO c.m.tranquility.kafka.KafkaConsumer – Flushed {dogakun={receivedCount=2, sentCount=2, droppedCount=0, unparseableCount=0}} pending messages in 0ms and committed offsets in 2ms.
上記みたいにsentCountに値がセットされていたら正常にdruidに取り込まれています。
droppedCountが0じゃない場合、何らかの問題があってdruidに取り込まれていません。
jsonのtimestamp(今回の場合だとdate)がUTCじゃない場合やテストデータなどでdruidのサーバーと時間がかけ離れてる場合にdropされたりします。
PlyQLでデータソースを確認
ちゃんとsentCountされた場合、PlyQLでデータが確認できるようになります。
bin/plyql -h localhost:8082 -q 'show tables' ┌────────────────────────────┐ │ Tables_in_database │ ├────────────────────────────┤ │ COLUMNS │ │ SCHEMATA │ │ TABLES │ │ sample │ └────────────────────────────┘ bin/plyql -h localhost:8082 -q 'select * from sample' ┌─────────────────────────────────────────┬──────────────┬─────────────────┬───────┬───────────────┬─────────────┬─────────┬────────────┬─────────┬─────────────┬─────────┬────────┐ │ __time │ browser_type │ browser_version │ count │ date │ ip │ os │ os_version │ referer │ ua_category │ ua_name │ vendor │ ├─────────────────────────────────────────┼──────────────┼─────────────────┼───────┼───────────────┼─────────────┼─────────┼────────────┼─────────┼─────────────┼─────────┼────────┤ │ Wed Apr 05 2017 17:52:45 GMT+0900 (JST) │ browser │ 9.0 │ 1 │ 1491382365000 │ 10.48.12.29 │ iPhone │ 9.1 │ NULL │ smartphone │ Safari │ Apple │ │ Wed Apr 05 2017 17:52:47 GMT+0900 (JST) │ browser │ 9.0 │ 1 │ 1491382367000 │ 10.48.12.29 │ iPhone │ 9.1 │ NULL │ smartphone │ Safari │ Apple │ │ Wed Apr 05 2017 17:52:51 GMT+0900 (JST) │ browser │ 57.0.2987.110 │ 1 │ 1491382371000 │ 10.48.12.29 │ Android │ 5.0 │ NULL │ smartphone │ Chrome │ Google │ │ Wed Apr 05 2017 17:52:54 GMT+0900 (JST) │ browser │ 57.0.2987.110 │ 1 │ 1491382374000 │ 10.48.12.29 │ Android │ 5.0 │ NULL │ smartphone │ Chrome │ Google │ │ Wed Apr 05 2017 17:52:57 GMT+0900 (JST) │ browser │ 9.0 │ 1 │ 1491382377000 │ 10.48.12.29 │ iPad │ 9.1 │ NULL │ smartphone │ Safari │ Apple │ └─────────────────────────────────────────┴──────────────┴─────────────────┴───────┴───────────────┴─────────────┴─────────┴────────────┴─────────┴─────────────┴─────────┴────────┘
こんな感じでSQLライクにデータを参照することができます。
Pivotの設定
imply入れたサーバーの9095ポートにアクセスします。
真ん中のcubes settingsまたは右上の設定アイコンからData Cubesを選んで、新しいdata cubeを作ります。
sourceにデータソース名を選択し、Timezoneは日本がないので Asia/Seoulを選択します。
Create cubeすると、data cubeが作られます。
今作ったdata cubeを選択するとこんな感じでCountが表示されます。
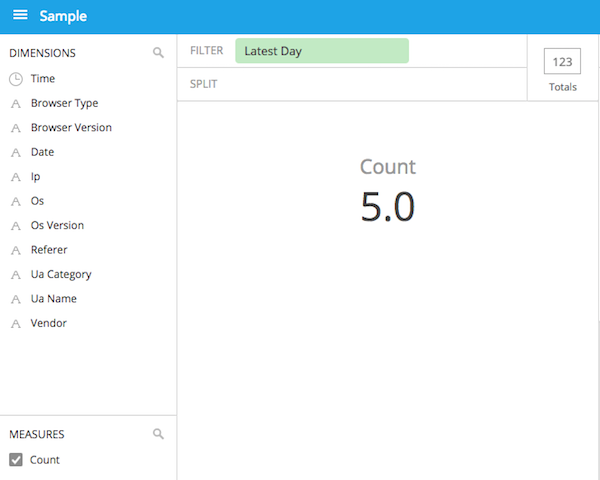
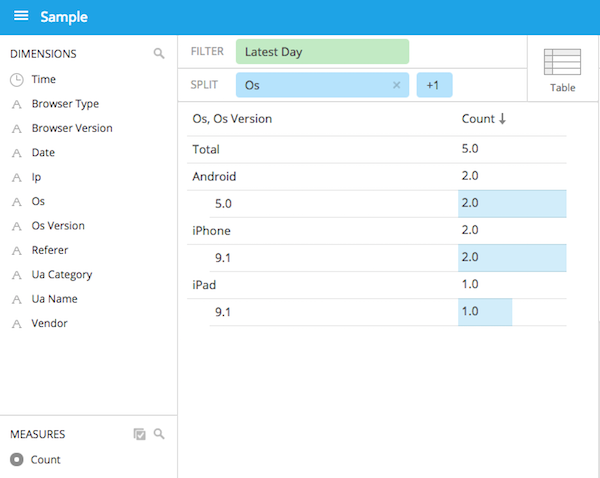
あとはディメンションを設定したりしてこんなグラフが作れます。
こんな感じで、implyとしてまとまったパッケージになったおかげで、別々に入れていたときよりも簡単に試せるようになりました。
↧
↧
Rustで株ボットつくってみた
会社の同僚に触発され、Rustの勉強も兼ねてSlackボットを作ってみました。

使ったライブラリなどを含めてご紹介させて頂きます。
※ 作成時のRustのバージョンは1.15.1です。
全体像

構成はシンプルです。
cronで30分毎にSlackボット(Rust CLI)を実行します。
Slackボットは起動すると指定株価一覧が記載されたCSVを読み込み、そこに記載された株の価格情報をGoogle Finance APIに取得しにいきます。
前日の終値から3%以上上昇もしくは3%以上下落した株の価格をSlackにメッセージとして送信します。
ソースコードはこちらに公開しています。
https://github.com/x1-/finance
※ Google Finance APIの詳細はこちらの記事をどうぞ。
プロジェクトの作成
Cargoを使ってプロジェクトのテンプレートを作成します。
CLIなのでバイナリ実行可能なように –bin オプションを付与します。
cargo new finance --bin
financeという名称で作成しました。
cd finance/
tree
.
├── Cargo.toml
└── src
└── main.rs
1 directory, 2 files
Cargo.toml に依存を書きます。
[dependencies] chrono = "0.3" csv = "0.14" docopt = "0.7" env_logger = "0.3" futures = "^0.1.7" hyper = "0.10" hyper-openssl = "^0.2.1" lazy_static = "^0.2.2" regex = "^0.2.1" rustc-serialize = "*" slack-hook = "0.3" time = "0.1" tokio-core = "^0.1.3"
多くのバージョンに ^ を付けて、パッチ・バージョンまで指定していますが、このように書くと「マイナー・バージョンが同じで、記載したパッチ・バージョンより高いバージョンのものがあればそちらを使う」ようになります。
メイン・プログラム
プログラムはシンプルで、APIのクライアントを記述した api_client.rs と main.rsの2ファイルのみとなっています。
全容は GitHub掲載のとおりですが、 メイン・プログラムを記述した main.rs を順に説明させて頂こうと思います。
いろいろな構造体の定義
はじめに、構造体をたくさん定義しています。
docoptで実行時引数を受け取るための構造体、CSVの各レコードを表す構造体、APIのレスポンスを受け取る構造体などです。
下記はCSVを解釈するための構造体です。
#[derive(Debug, RustcDecodable)]
struct Record {
code: String,
name: String,
market: String
}
Debug を付与しないと printできません。
RustcDecodable を付与すると csv でパースできるようになります。
csv は内部的に rustc_serialize を使っているのですね。
docopt用usage文字列の作成
const USAGE: &'static str = r" to notice kabu rate of up or down at slack-channel. Usage: finance --tick=<tick> --ratio=<ratio> [--webhook=<url>] [--term=<term>] [--data=<csv>] finance --version Options: -h --help Show this message. --version Show version. --tick=<tick> candle tick interval by seconds [default 86400]. --ratio=<ratio> the threshold ratio of price up or down [default 0.1]. --webhook=<url> webhook url of slack integration. if empty, do not send slack [default empty]. --term=<term> the term of measuring price [default 7d]. --data=<csv> the csv listed the stocks [default ./data/stocks.csv]. ";
ここの部分はdocoptに渡すusage文字列を定義しています。
pythonのdocoptと似ていますが、pythonのものほど柔軟性はありません。。。
tick などに default値を定義していますが、これが解釈されてデフォルト値として扱われるわけではありません。
引数が渡されなかった場合、空文字として扱われます。
よって数値引数が渡されなかった場合、エラーとなります。
clapだとどうなのか気になるところ。
各クライアントの生成
Google FinanceのAPIクライアントは hyper のHTTPクライアントを使って作成しました。
SSLを解釈できるHTTPクライアントが hyper くらいしかありませんでした。
let client = api_client::Ssl::new();
Slack投稿クライアントにはslack-hookを使いました。
今回は株の上昇幅を投稿するだけだったのでシンプルなslack-hookを選択したのですが、会話するなら Yobotとかなのかな。
let slack = Slack::new( args.flag_webhook.as_str() );
値動きを追う株
Slackに投稿する対象の株を data/stocks.csvに定義しています。
※ 将来的にはDB管理もありかなと。
CSVファイルの読み込みには便利なcsvライブラリを使っています。
これを使うとCSVファイルを RustcDecodable な構造体のベクターにマッピングできます。
let mut file = csv::Reader::from_file( args.flag_data ).unwrap();
データ・ファイルのパスも実行時引数としていますが、これはデフォルトを data/stocks.csv にしています。
データを取得して条件に該当する株価をSlackにポスト
CSVから取得したレコードを1行つ処理し、 Google Finance APIに現在の株価を問い合わせます。
前日の終値から3%以上上昇もしくは3%以上下落した株の価格をSlackにメッセージとして送信します。
for r in file.decode() {
let r: Record = r.unwrap();
let url = format!(
"{uri}&p={term}&i={tick}&x={market}&q={code}",
uri = URL_BASE,
term = args.flag_term, tick = args.flag_tick, market = "TYO", code = r.code );
let res = &client.sync_get( &url );
let data: Result<Vec<Stock>, String> = data_to_struct( res, args.flag_tick );
let rprice: Result<ComparedPrice, String> = data.and_then( |d| close_rate( &d ) );
match rprice {
Ok( ref p ) if p.ratio >= args.flag_ratio || p.ratio < -(args.flag_ratio) => {
let payload = slack_payload( r.code, r.name, p.current, p.previous, p.ratio );
if let Ok(ref s) = slack {
let res = s.send( &payload );
println!("res: {:?}", res);
}
println!("found: {:?}", payload);
},
Ok( ref p ) => println!( "rate is less than {th}. ratio:{ratio:.3}, [{code}:{name}, now:{current}]", th = args.flag_ratio, ratio = p.ratio, code = r.code, name = r.name, current = p.current ),
_ => println!( "cannot calculate ratio" )
}
}
投稿アイコンに絵文字を使えるので、上昇した株は :chart_with_upwards_trend: 、下降した株は :chart_with_downwards_trend: を使って上昇/下降をわかりやすくしています。
ざっとこんな感じのプログラム構成になっています。
私はこれを使って仕事中に注目している株の値動きをウォッチしています。
使ったライブラリまとめ
| ライブラリ | 用途 |
|---|---|
| chrono | 日時文字列を変換したり、日時計算したり。 |
| csv | APIから取得したデータをパース。 |
| docopt | コマンドライン引数のパースに。clapにしておけばよかったかなあ… |
| env_logger | ログを出力。 |
| hyper | HTTPクライアントを作成。 |
| hyper-openssl | APIがSSLだったので。 |
| lazy_static | グローバル変数の実行時初期化に。 |
| regex | 正規表現に。 |
| slack-hook | Slackにメッセージを送信。 |
↧
DruidのデータをSupersetで可視化する
![]()
implyにはDruidのBIツールのpivotが入っているのですが、機能が少ない上に確か一定期間後に有料だった気がするので、オープンソースのSupersetを入れることにします。
このsupersetは以前書いた記事で、panoramixという名前で開発されていましたが、supersetという名前になりAirbnbのもとで開発が進められるようになったみたいです。
panoramixの時もいろんなグラフが生成できましたが、supersetでは更にパワーアップしています。
もちろんデータソースはDruidだけではなく、各RDBとも接続できます。
インストール
supersetはpython製なのでpipでサクッと入るのですが、python2.7、python3.4以上なので2.6だと動きません
インストールはドキュメントどおりにやっていけば大丈夫ですが、途中で必要なライブラリが色々出てきたりするので環境によっては若干つまづくかも。
ドキュメントではvirtualenvで入れてますが、自分はanacondaの2.7を入れました。
あとこの辺も自分の環境では必要でした。
yum install gcc-c++ cyrus-sasl-devel openssl-devel
Druidとつなぐ
druidと繋ぐ前に、druid側でDatasourceの設定が必要です。前回のimplyの設定の項目でやった、conf-quickstart/tranquility/kafka.json のことですね。
さて、supersetインストール時に設定した管理者アカウントでsupersetにアクセスします。
そして上部タブのSourcesのDruid Clustersにアクセスし、Druid Clusterを設定します。これはDruidを1台のマシンで動かしてても必要です。
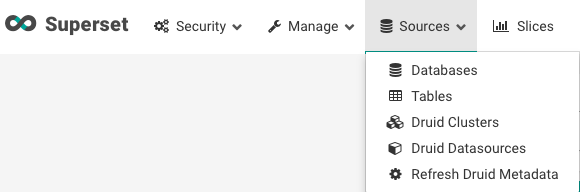
Druid Clusterを+ボタンを押して追加します。

今回サーバーが1台だけで試してるので、Coodinator Brokerがlocahostですが、他のサーバーで動いている場合はHostのIPを指定します。
クラスターを作成したら、上部タブのSourcesのRefresh Druid Metadataをクリックすると、自動でDruidの設定ファイルからDatasourceが読み込まれます。
Datasourceが作成されたら、まず編集します。
Druidでは基本的に時間をUTCで管理してるので、Time Offsetに日本時間の9を設定します。
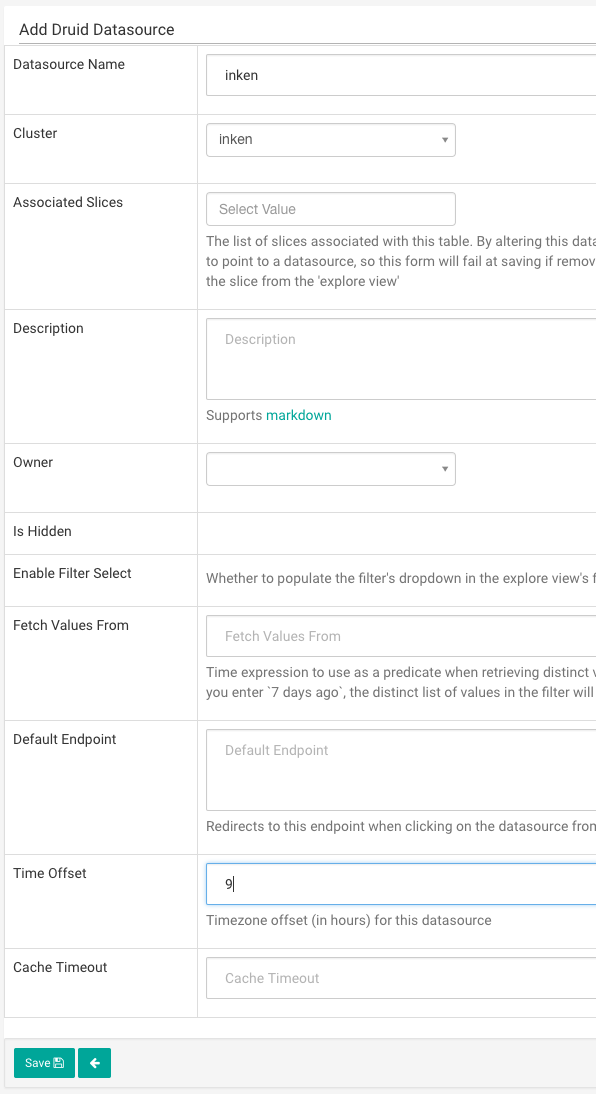
List Druid Column、List Druid Metricも設定ファイルどおりにカラムが追加されているか確認します。
たまにRefresh Druid Metadataやっても読み込まれない場合があるので、その場合は手動でカラムなどを追加します。
Supersetではカラム名に別名をつけることができます。

編集画面の Dimension Spec Jsonで指定します。上記の例はDruid上ではosというカラム名ですが、superset上ではos_nameというカラム名に変更しています。
ただ、現状では名前を変更するとクエリのfilterで指定した際に動かなかったりとサポートされていない機能があるので、そのままの名前を使うほうがいいと思います。
Sliceを作りダッシュボードに貼る
SoucesタブのDruid Datasourcesからデータソースを選び、グラフを作っていきましょう。
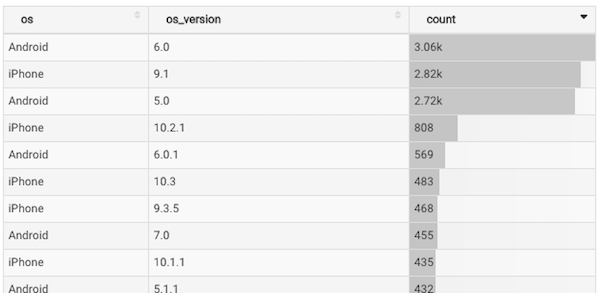
上の例ではTable Viewで各スマホOS使用数を出してみました。
こんな感じで簡単にいろんなグラフやチャートが作れます。
saveしてダッシュボードを新規作成して、完成です。
supersetのダッシュボードは良くできていて、各スライスの大きさや位置がかなり自由に配置できます。
なのでこんなダッシュボードも簡単に作れます。
現状ではダッシュボードのテーマを変えたりはできないみたいですがCSSを記述できるので、自分好みのCSSを当てることもできます。
こんな感じでDruidとさくっとつなげてとても便利なBIツールだと思いました。
↧
マインクラフトみたいなWeb Blocksを触ってみる
久々の動画はゆるい感じのを
何番煎じかだけど
↧